 StudyXiao
StudyXiao使用 SQLAlchemy 与数据库打交道。
是什么
SQLAlchemy 是一个 Python SQL 工具包(core)和对象关系映射器(ORM),它提供了一系列的工具,使得 Python 开发者能够在关系数据库(MySQL)上使用 SQL。
SQLAlchemy 的核心是 SQL 工具包,它提供了 SQL 表达式语言,它允许用户使用 Python 语言来编写 SQL 语句。SQLAlchemy ORM 则是在 SQL 工具包的基础上,提供了一个对象关系映射器,它允许用户使用 Python 语言来操作数据库,而不需要直接使用 SQL 语句。
为什么
- ORM:ORM 是一种编程技术,它将对象模型(类)与数据库模型(表)进行映射,从而将对象操作转换为数据库操作。ORM 使得开发者可以使用面向对象的方式来操作数据库,而不需要直接使用 SQL 语句。
- 安全:SQLAlchemy 提供了一系列的工具,使得开发者能够使用 Python 语言来编写 SQL 语句,从而避免了 SQL 注入攻击。
- 跨数据库:SQLAlchemy 支持多种数据库,包括 MySQL、PostgreSQL、Oracle、SQLite、Microsoft SQL Server 等。
有什么
SQLAlchemy 提供了两个核心的模块:SQL 工具包(core)和 ORM。
- SQL 工具包:SQL 工具包提供了 SQL 表达式语言,它允许用户使用 Python 语言来编写 SQL 语句。
- ORM:ORM 则是在 SQL 工具包的基础上,提供了一个对象关系映射器,它允许用户使用 Python 语言来操作数据库,而不需要直接使用 SQL 语句。
- 其他:SQLAlchemy 还提供了一些其他的模块,包括数据库连接池等。
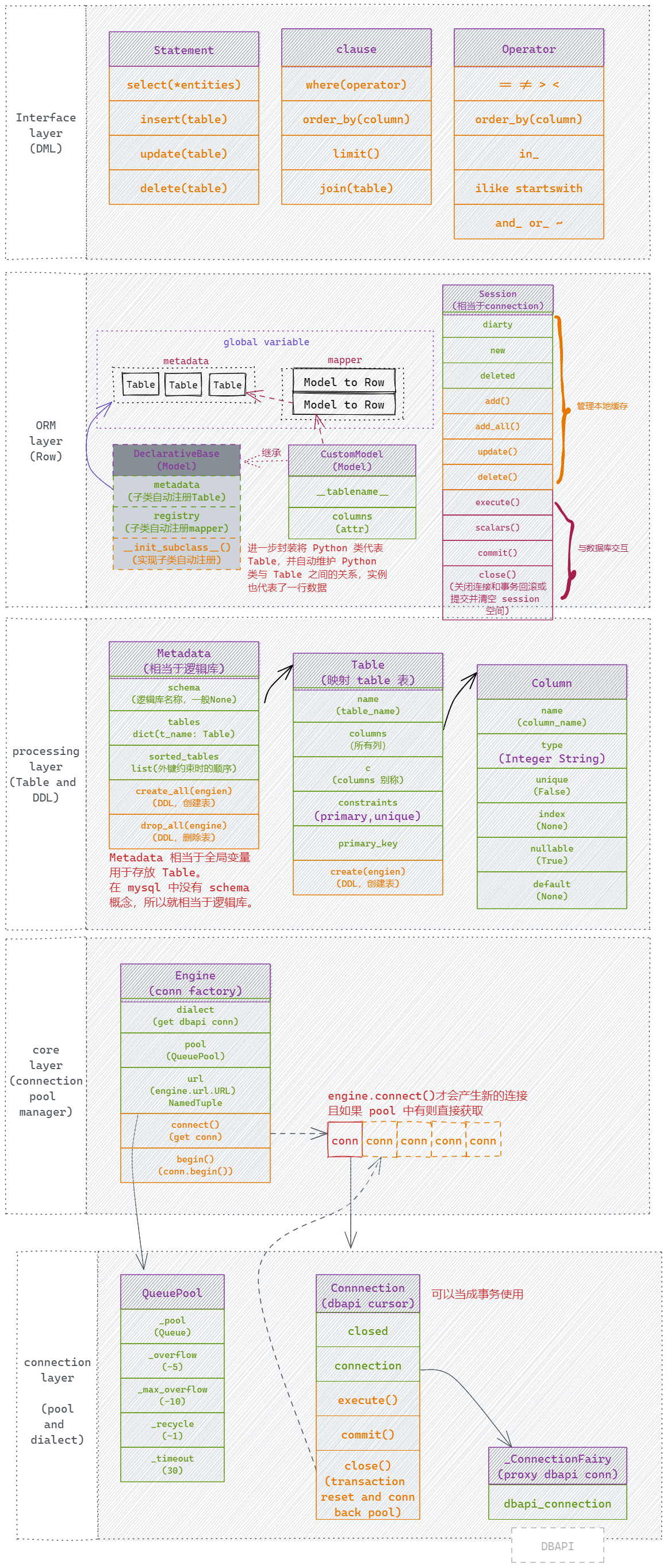
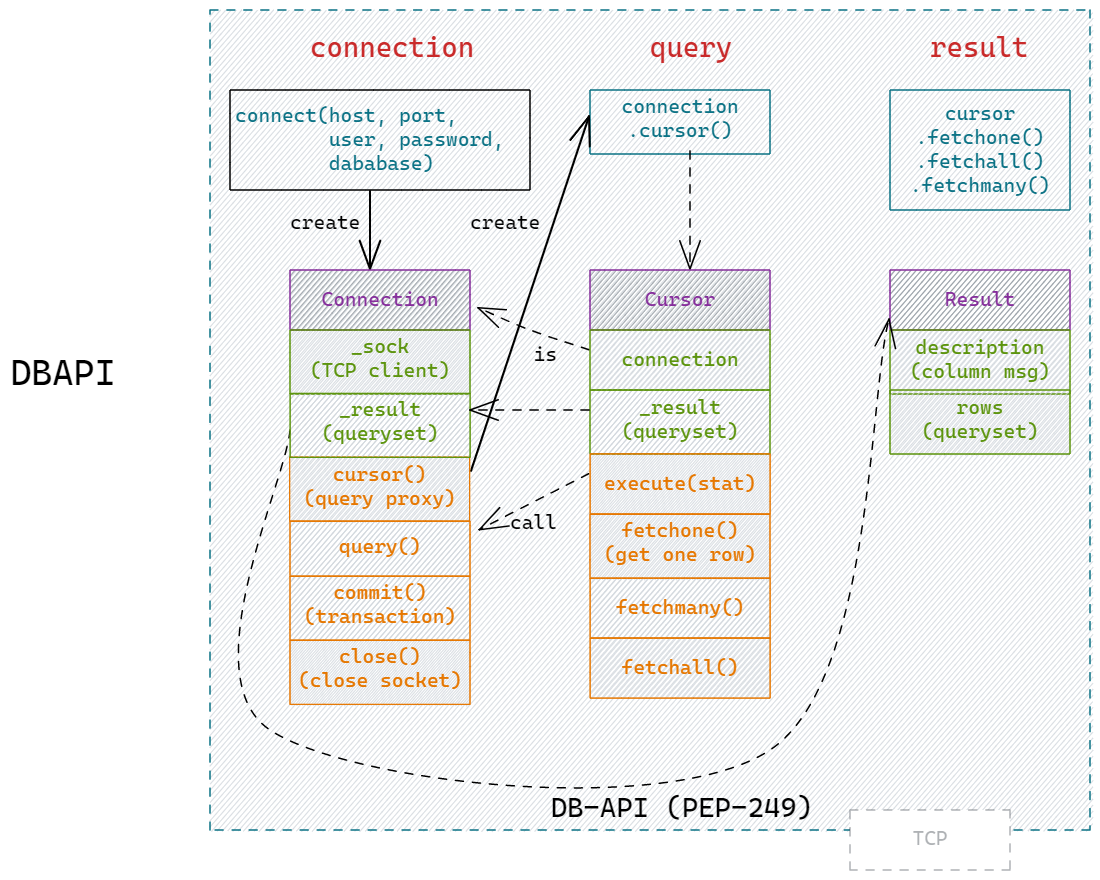
怎么用
Engine:create_engine()创建连接DeclarativeBase:class BaseModel(DeclarativeBase)创建基类,用来 DDL 操作,包含了 metadata 和 mapper,这两个对象是 SQLAlchemy ORM 的核心,用来将 Python 对象映射到数据库中的表。子类化 DeclarativeBase 时会初始化 register,这个 register 在之后的子类化中会自动将当前 Table 注册到 metadata 和 mapper。实际是 metadata 在 DDL 操作。Table:class Demo(BaseModel)使用 Python 对象表示数据库中的表,实例表示row。Column:mapped_column()创建映射列,可以充分利用 Python 的type hints,比如 int 只在 Python 中表示整数,而数据库中需要使用 integer。column_property()可以定义数据库表达式,会发出查询语句@hybrid_property可以当作列发出查询语句
Session:Session(engine)用来 DML 操作本地实例缓存(obj)和远程数据库Row,需要绑定到 Engine,并使用 engine 的 session 进行远程事务操作。注意Session 并不是包含于 Engine 的关系,Session 可以 bind 多个 Engine,这里为了简便理解将其归于 Engine。execute(statement)执行 SQL 语句,返回结果集。select()查询语句,返回结果集。insert()插入语句,返回插入的主键。update()更新语句,返回更新的行数。delete()删除语句,返回删除的行数。
scalar()返回单个值。scalars()返回多个值。get()根据主键查询,返回单个对象。commit()提交事务。rollback()回滚事务。
安装
pdm add sqlalchemy连接数据库
from sqlalchemy import create_engine
# 创建数据库引擎
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')- echo:是否打印日志,默认为 False。
- pool_size:连接池大小,默认为 5。
- max_overflow:连接池溢出大小,默认为 10。(超过连接池后允许的最大连接数)
- pool_recycle:连接池回收时间,默认为 -1,即永不回收。会造成连接池中的连接失效,所以需要设置为一个合理的值,比如 3600 秒。
- more
创建表
为什么需要子类化 DeclarativeBase
首先解释几个概念:
Table:使用 Python 对象表示数据库中的表,实例表示row。
Metadata:集中存放所有 Table的地方,可以方便 DDL。
Mapper:表示如何将 Python Object (Table 对象)映射到 数据库中的表,比如 int只在python中表示整数,而数据库中需要使用 integer。这就是mapper需要做的,当然 sqlalchemy 已经将常用的都写好了,所以使用时只需要定义 Table 对象(并添加到 metadata),然后将 Table注册到mapper即可。DeclarativeBase在子类化时会初始化 register,这个register在之后的子类化中会自动将当前Table注册到metadata和mapper。
再来看 DecllarativeBase 源码:
class DeclarativeBase(
inspection.Inspectable[InstanceState[Any]],
metaclass=DeclarativeAttributeIntercept,
):
def __init_subclass__(cls) -> None:
if DeclarativeBase in cls.__bases__:
# 当直接子类化 DeclarativeBase 时初始化 register(包括 mapper 和 metadata)
_check_not_declarative(cls, DeclarativeBase)
_setup_declarative_base(cls) # 这个就是初始化的过程
else:
# 在之后的孙子类中直接使用上面初始化的register进行映射
_as_declarative(cls._sa_registry, cls, cls.__dict__)
super().__init_subclass__()控制子类化过程,自动将Table对象注册,所以需要先子类化一个Base,这样Base就有了register的类变量,然后再继承自Base时会自动注册当前对象到 register的metadata和mapper。
另外因为 DeclarativeAttributeIntercept 的作用,当在DeclarativeBase 的直接子类定义类变量时会注册到 __mapper__ 属性中。而孙子类需要使用 __mapper_args__ 属性。在孙子类中还可以通过@declared_attr 装饰器将类方法当作 mapper 参数。
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
from sqlalchemy.ext.hybrid import hybrid_property
# 创建数据库引擎
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
# 创建基类
class BaseModel(DeclarativeBase):
pass
# 创建表对象
class User(BaseModel):
__tablename__ = 'user'
id: Mapped[int] = mapped_column(Integer, primary_key=True)
name: Mapped[str] = mapped_column(String(20))
age: Mapped[int | None] = mapped_column(Integer)
@hybrid_property
def fullname(self):
"""实例查询"""
if self.firstname is not None:
return self.firstname + " " + self.lastname
else:
return self.lastname
@fullname.expression
def fullname(cls):
"""发出语句"""
return case(
(cls.firstname != None, cls.firstname + " " + cls.lastname),
else_=cls.lastname,
)
# 创建表(一般只做表映射,创建表由 alembic 或数据库管理员完成)
BaseModel.metadata.create_all(engine)插入数据
为什么需要使用 session
SQLAlchemy 使用 Session(不同于数据库的session)对象来作为 unit of work 来进行 DML 操作,它可以:
- 管理本地实例副本
- 使用数据库事务远程连接
- 执行 DML 语句
通过Session来管理本地实例,每个Session都会产生一个connection(包含事务),并将所有查询或需要持久化的 ORM 对象缓存起来,通过 commit() 进行持久化。相当于数据库的本地副本。其中的对象(row)不能脱离 Session 进行使用,且对象包含了几种不同状态(new、dirty、deleted等)这些都是暂存状态,必须 commit() 才能与远程同步。persistent 表示与远程数据是一致的。
特别的,每个线程应该使用唯一 Session(每个Session对应一个数据库事务),不可以跨线程使用。
engine = create_engine(...)
Session = sessionmaker(engine)
with Session() as session:
session.add(User)
session.commit()操作的对象称为 Entry。
Entry: 一般指的是数据库中的一行数据,也可以是某些列,比如select(User, User.name)其中User和User.name都可以称为Entry,select()中有几个Entry,执行session.execute()就会返回几个元素的命名元组对象(可以通过.获取)
from sqlalchemy.orm import sessionmaker
# 创建会话
Session = sessionmaker(bind=engine)
session = Session()
# 插入数据
with session:
session.add(User(name='Tom', age=20))
session.commit()查询数据
with session:
# 查询所有数据
statement = select(User)
result = session.execute(statement).all()
for row in result:
print(row.name, row.age)
# 返回的是 [(User1,), (User2)] 这样的元组列表
# 一般会使用 scalars() 将 [(User1,), (User2)] 展开成[User1, User2]
result = session.execute(statement).scalars().all()
for row in result:
print(row.name, row.age)
# 查询第一条数据
statement = select(User).limit(1)
result = session.execute(statement).first()
print(result.name, result.age)
# 查询指定数据
statement = select(User).where(User.name == 'Tom')
result = session.execute(statement).all()
for row in result:
print(row.name, row.age)
# 查询指定列
statement = select(User.name, User.age)
result = session.execute(statement).all()
# 返回的是 [(name, email), (name, email)]
for name, age in result:
print(name, age)更新数据
with session:
# 更新数据
statement = update(User).where(User.name == 'Tom').values(age=21)
session.execute(statement)
session.commit()删除数据
with session:
# 删除数据
statement = delete(User).where(User.name == 'Tom')
session.execute(statement)
session.commit()